
Custom automation vs no-code
Compare Zapier alternative and Make vs Zapier options, then decide when custom Python automation is better for reliability, observability, control, or private deployment.
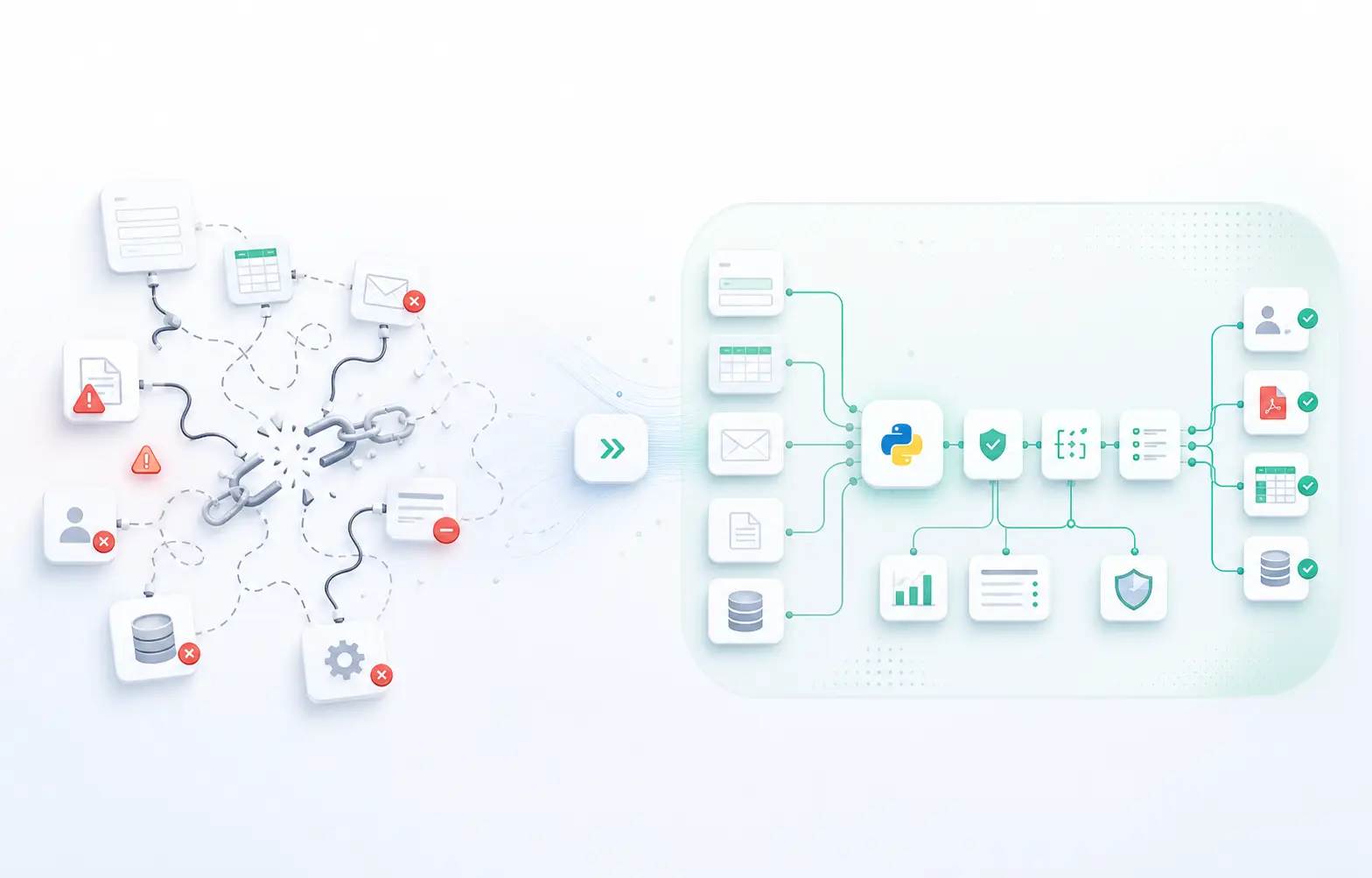
When no-code fits
Simple internal tasks with low risk and low complexity.
When custom wins
Repeated workflows, sensitive data, or systems that need traceability.
What we recommend
Use the simplest thing that can work, but move to custom automation when the workflow becomes business-critical.
What the decision usually comes down to
The point is not to reject no-code entirely. The point is to know when the workflow has outgrown a tool stack and needs custom code, observability, and private deployment.
When no-code is enough
Low-risk automations, light volume, simple branching, and data that can safely move through a vendor tool.
Signals you have outgrown it
Silent failures, rate limits, brittle branches, debugging overhead, and manual exceptions that keep piling up.
Why custom wins
You get reliability, logs, retries, control over the data flow, and workflows shaped around the business process.
Why the cost changes
A cheap stack can become expensive once volume, retries, debugging, and maintenance start repeating every month.
How the tradeoff usually shows up in practice
The choice is rarely abstract. It usually shows up as debugging time, process risk, missing logs, and the amount of manual cleanup your team still needs after every run.
Factor
What you compare
No-code tools
Fast to start, good for simple paths
Custom automation
Best for control, logs, and private workflows
Our default call
What we advise by default
Reliability
Data sensitivity
Debugging
Examples of workflows that usually outgrow no-code
These are the kinds of business processes that tend to start simple and then become worth rebuilding once reliability, logging, and private execution matter more than the convenience of the original tool stack.
CRM routing and follow-up
Lead enrichment, assignment, reminders, and handoffs are easy to start in no-code. They get brittle when routing logic grows, retries matter, or sales operations needs logs for every update.
Document and proposal generation
Drafting letters, proposals, and internal documents can begin as templates and forms, but custom automation becomes better when variables, approvals, and batch output must stay traceable.
Private or regulated workflows
If the process touches sensitive data, needs on-premise behavior, or must stay away from a third-party stack, private Python automation is usually the cleaner long-term fit.
How we decide whether to keep a workflow in no-code or rebuild it
We start with the workflow itself, not the tool stack. If a process is rare, low-risk, and easy to explain, a no-code tool can be the right answer.
When the same process becomes repetitive, high-value, or fragile, we look at custom automation so the team gets logs, retries, private execution, and cleaner handoffs.
That is why the best comparison is not tool versus tool. It is business process versus business process, with the implementation chosen for reliability and control.
Keep no-code
Simple, low-risk, low-volume tasks.
Consider custom
Repeated workflows with critical handoffs.
Move now
Sensitive data, debugging pain, or failed runs.
Questions teams ask before moving beyond no-code
How do we know the workflow is too complex?
If support time, debugging, or manual cleanup starts to rival the time saved, the workflow is probably ready for custom automation.
What happens to our existing automations?
We usually keep what still works and replace only the brittle or high-risk paths so the migration stays practical.
Can custom automation still be lightweight?
Yes. The goal is not to overbuild. The goal is to make the workflow reliable, traceable, and easier to maintain.
Does this mean we should abandon Zapier or Make?
No. We use the simplest tool that fits the job, then move only the flows that need more control or a private runtime.
If the workflow needs more control, these service pages are the next step
The comparison works best when it leads to the specific page that matches the workflow. Use the page that fits the problem, then keep the implementation simple, traceable, and private where needed.